1. Классификация
моделей данных
Модель данных - это некоторая абстракция,
которая, будучи приложима к конкретным данным,
позволяет пользователям и разработчикам трактовать их уже как информацию, то
есть сведения, содержащие не только данные, но и взаимосвязь между ними.
Индексно-последовательная
модель данных (до 1968 г.)
БД представляет собой
совокупность логически взаимосвязанных файлов данных определенной организации.
Совокупность файлов БД определяется посредством схемы, не зависящей от
программ, которые к ней обращаются, БД реализована на основе прямого доступа.
При создании И-П файла создается так называемый индекс, который служит для
быстрого доступа к записям по значению ключевого поля. Следует обратить
внимание на то, что делит файл на записи и поддерживает индекс сама ОС, а не
исполняющая система, скомпонованная с прикладной программой. С И-П файлами
можно работать двояко. Во-первых, можно считывать записи последовательно, одну
за другой. Во-вторых, можно сразу находить нужную запись по значению ключевого
поля, при этом ОС использует индекс для ускорения поиска. И-П файлы - большой
шаг вперед по сравнению с плоскими файлами. Тем не менее, и они не лишены
недостатков:
• В одном файле могут
храниться только сущности одного вида. Создание сложной модели данных приведет
к нагромождению большого количества ничем не связанных между собой файлов.
• Отсутствие средств для описания взаимосвязей между сущностями, хранящимися
в различных файлах. Об этих взаимосвязях «знает» только прикладная программа,
обрабатывающая данные.
Иерархическая модель данных (1968-1980е)
В основе иерархических СУБД лежит довольно простая
модель данных, которую можно представить себе в виде дерева. Дерево состоит из
вершин, каждая из которых, кроме одной, имеет единственную родительскую вершину
и несколько (в том числе ни одной) дочерних. Вершина, не имеющая родительской,
называется корнем дерева. Вершины, не имеющие дочерних,
называются листьями. Остальные вершины являются ветвями. Иерархические базы
данных наиболее пригодны для моделирования структур, по своей природе
являющихся иерархическими. Тем не менее, существует значительное количество
структур, не сводящихся к простой иерархии. Например, всем известное
генеалогическое дерево, которое на самом деле не является деревом в строгом смысле, поскольку у
большинства людей по два родителя. Иерархические СУБД быстро прошли пик
популярности, которая обусловливалась их простотой в использовании и ранним
появлением на рынке, когда основные конкуренты еще не дозрели для коммерческого
использования. Затем их многочисленные недостатки сделали их
неконкурентоспособными, и в настоящее время иерархическая модель представляет
исключительно исторический интерес.
Недостатки:
·
дублирование
данных, сложность в организации выборки информации.
·
сложность в организации выборок информации.
Примеры (IMS –
первая СУБД фирмы IBM, ADABAS).
Сетевая модель данных (60-80е)
Подобно иерархической,
сетевую модель также можно представить себе в виде ориентированного графа. Но в
этом случае граф может содержать циклы, т.е. вершина может иметь несколько
родительских. В этой модели вершины представляют собой сущности, а соединяющие
их ребра - отношения между ними. Сетевые СУБД имели гораздо больший успех и
долго господствовали на рынке СУБД. Достоинством сетевой модели данных является
возможность эффективной реализации по показателям затрат памяти и
оперативности. Недостатком сетевой модели данных являются высокая сложность и
жесткость схемы БД, построенной на ее основе.
Сетевые базы данных
подобны иерархическим, за исключением того, что в
них имеются указатели в обоих направлениях, которые соединяют родственную
информацию.
Несмотря на то, что эта модель решает
некоторые проблемы, связанные с иерархической моделью, выполнение простых
запросов остается достаточно сложным процессом.
Также, поскольку логика процедуры выборки
данных зависит от физической организации этих данных, то эта модель не является
полностью независимой от приложения. Другими словами, если необходимо изменить
структуру данных, то нужно изменить и приложение.
Реляционная модель данных (70е-...)
Разработана Коддом. Реляционные СУБД являются в настоящий момент
самыми распространенными. Их реализации существуют на всех мало-мальски
пригодных для этого платформах, для всех операционных систем и для всех
применений. База данных выглядит как простой набор взаимосвязанных таблиц. Но
за внешней простотой кроется мощный и вместе с тем изящный математический
аппарат реляционной алгебры, которая в свою очередь базируется на целом ряде
математических дисциплин, среди которых - логика, исчисление предикатов, теория
множеств. Немалую роль в успехе реляционных СУБД играет также язык SQL,
разработанный специально для запросов к реляционным БД. SQL объединил в себе
функции описания данных и манипулирования ими. Но самой привлекательной его
особенностью, особенно для пользователей-непрофессионалов в программировании,
является то, что можно строить запросы на основе непроцедурного подмножества
SQL. Это означает, что в формулировке запроса указывается, что должно
содержаться в результате, а не как его получить.
Объектно-ориентированная модель (80-90)
Данные оформлены в виде
моделей объектов, включающих прикладные программы, которые управляются внешними
событиями. Результатом совмещения возможностей (особенностей) баз данных и
возможностей объектно-ориентированных языков программирования являются
Объектно-ориентированные системы управления базами данных. ООСУБД расширяет
языки программирования (Python, Java,
C#, Visual Basic .NET, C++,
Objective-C и Smalltalk),
прозрачно вводя долговременные данные, управление параллелизмом, восстановление
данных, ассоциированные запросы и другие возможности. Объектно-ориентированные
базы данных обычно рекомендованы для тех случаев, когда требуется
высокопроизводительная обработка данных, имеющих сложную структуру. Характеристики:
поддержка сложных объектов (применение конструкторов объектов), поддержка
уникальности объектов, инкапсуляция, поддержка типов и классов, наследование,
вычислительная полнота, расширяемый набор типов данных.
XML (2003-...)
В XML-модели данных многие
объекты данных приложения определяются на XML. Так как XML имеет иерархическую
структуру, легко понять взаимосвязь между объектами данных в естественном,
удобном для чтения формате. Для управления этими метаданными в приложении
используется объектная модель документа (document object model, DOM). Преимущества:
уменьшение объема кода (повышение его читабельности), усовершенствованные
возможности поиска и навигации, встроенные проверки ограничений и проверка по
схеме. Недостатки: сложность преобразования в/из реляционной модели, усложняется процесс изучения и
профессионального освоения интерфейсов DOM и их реализаций, а также навигации и
поиска в иерархии XML.
2. Понятие базы данных. Основные характеристики баз данных
База данных – это организованная совокупность данных и их
описаний, хранящихся вместе. Эта совокупность независима от прикладных программ
и обрабатывается с помощью специальных средств СУБД. Независимость данных от
прикладных программ рассматривается с двух сторон:
- когда происходят изменения в БД, они не должны отражаться на структуре
прикладных программ.
- когда происходят изменения в приложениях (ПП), они
не должны влиять на структуру БД.
Банк данных - автоматизированная информационная система
централизованного хранения и коллективного использования данных. В состав банка
данных входят одна или несколько баз данных, справочник баз данных, система
управления базами данных, а также библиотеки запросов и прикладных программ.
Данные – это информация, зафиксированная в определенной (структурированной)
форме, пригодной для последующей обработки, хранения и передачи.
Языковые средства – языки, с помощью которых описывается структура
данных (DDL) и языки манипулирование данными (SQL).
Обобщение представлений
всех пользователей о данных называется концептуальной моделью (схемой)
БД. Концептуальная модель представляет информационное описание предметной
области с учетом логических взаимосвязей, поэтому её еще называют инфологической
(информационно-логической) моделью.

Предметная область - часть реального мира, подлежащая изучению с целью
организации управления и, в конечном счете, автоматизации.
Информационная система
требует создания в памяти ЭВМ динамически обновляемой модели внешнего
мира с использованием единого хранилища - базы данных. Словосочетание
"динамически обновляемая" означает, что
соответствие базы данных текущему состоянию предметной области обеспечивается
не периодически, а в режиме реального времени. При этом одни и те же данные
могут быть по-разному представлены в соответствии с потребностями различных групп
пользователей.
Отличительной чертой баз
данных следует считать то, что данные хранятся совместно с их описанием, а в
прикладных программах описание данных не содержится. Независимые от программ
пользователя данные обычно называются метаданными. В ряде современных
систем метаданные, содержащие также информацию о пользователях, форматы
отображения, статистику обращения к данным и др. сведения, хранятся в
словаре базы данных.
3. Методика проектирования
баз данных. Этапы проектирования баз данных
1.
Проектирование БД
o
Описание
предметной области. Предметная область - часть реального мира, подлежащая
изучению с целью организации управления и, в конечном счете, автоматизации.
Предметная область представляется множеством фрагментов, каждый фрагмент
характеризуется множеством объектов и процессов, использующих объекты, а также
множеством пользователей, характеризуемых различными взглядами на предметную
область.
o
Постановка задач
2.
Выявление
сущностей и связей между ними. Атрибуты – свойства характеристики сущности.
Сущность – реальный объект предметной области.
3.
Построение
инфологической модели данных (IMD). Основными
конструктивными элементами инфологических моделей являются сущности, связи
между ними и их свойства (атрибуты). IMD не
зависит от СУБД и отражает структуру предметной области и взаимодействие
объектов предметной области. IMD может быть представлена в виде схемы данных с помощью
определенных нотаций (Чена, IDEF1X, UML)
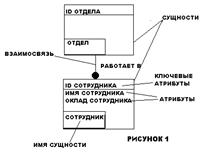
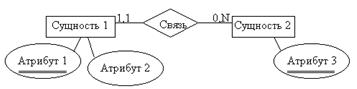
4.
Выбор типа СУБД
5.
Разработка даталогической модели. Даталогическая
модель опирается на СУБД и содержит структуру БД.
6.
Проектирование
модели данных с помощью нормальных форм (для реляционной БД).
7.
Разработка модели
данных с помощью CASE-средств
(Computer Aided Software Engineering), разработка
концептуальной модели данных. Концептуальная модель показывает структуру данных
с разных сторон:
o
сущности, их
атрибутов и связи между сущностями
o
первичные,
внешние ключи, возможные индексы
o
типы данных,
ограничения, правила. (Логический и физический уровень).
8.
Выбор СУБД
9.
Конвертирование
схемы данных в среду СУБД
10.
Заполнение БД,
тестирование.
С пункта 9 нельзя вернуться к предыдущим пунктам.
4. Реляционная модель данных. Основные понятия
Принципы реляционной
модели были сформулированы в 1969—1970 годах Э.Ф. Коддом (E.F.Codd).
Реляционная модель данных — логическая модель данных, прикладная теория,
описывающая структурный аспект, аспект целостности и аспект обработки
данных в реляционных базах данных.
·
Структурный аспект— данные в базе данных представляют собой
набор отношений. Единственной структурой
данных, используемой в реляционной модели, являются нормализованные n-арные отношения.
·
Аспект целостности — отношения (таблицы) отвечают определенным условиям целостности. РМД
поддерживает декларативные ограничения целостности уровня домена (типа данных),
уровня отношения и уровня базы данных. Целостная
часть описывает ограничения
специального вида, которые должны выполняться для любых отношений в любых
реляционных базах данных. Это целостность сущностей и целостность
внешних ключей.
·
Аспект обработки (манипулирования) — РМД поддерживает операторы манипулирования
отношениями (реляционная алгебра, реляционное исчисление).
Реляционная модель
требует, чтобы типы используемых данных были простыми (логический, строковый,
численный), нет никаких указателей (адресов), связывающих одно значение с
другим;
Кроме того, в состав реляционной модели данных обычно
включают теорию нормализации.
Реляционная модель данных является приложением к
задачам обработки данных таких разделов математики как теория множеств и
формальная логика.
Отношение – это декартово произведение доменов атрибутов.
Реляционное отношение – это таблица особого вида, представляющая собой
множество объектов, обладающих схожими характеристиками.
Объекты,
обладающие схожими характеристиками – записи.
Атрибут,
значение которого однозначно идентифицирует кортежи, называется ключевым(Первичный ключ)
Количество
объектов в одном отношении – мощность
отношения.
Количество
атрибутов в отношении определяет степень
отношения.
Кортеж – пара: имя атрибута - значение атрибута.
Домен – множество возможных значений атрибута. (понятие домена имеет семантическую нагрузку: данные можно
считать сравнимыми только тогда, когда они относятся к одному домену. Таким образом, в рассматриваемом нами примере сравнение атрибутов
"Табельный номер" и "Оклад" является семантически
некорректным, хотя они и содержат данные одного типа.)
Для
отражения ассоциаций между кортежами разных отношений используется дублирование
их ключей. Внешний ключ – это
атрибут кот. располагается в
зависимом отношении и определен на том же самом домене, что и первичный ключ
главного отношения.

Свойства
отношений:
1. Уникальность
атрибутов. Из
этого свойства вытекает наличие у каждого кортежа первичного ключа.
2.
Неупорядоченность атрибутов. Для ссылки на значение атрибута всегда используется
имя атрибута.
3. Неупорядоченность
кортежей.
4. Атомарность
значений атрибутов. т.е.
среди значений домена не могут содержаться множества значений (отношения).
5. Нормальные
формы отношений
Нормальная форма — свойство отношения в реляционной модели данных, характеризующее его
с точки зрения избыточности, которая потенциально может привести к логически
ошибочным результатам выборки или изменения данных. Нормальная форма
определяется как совокупность требований, которым должно удовлетворять
отношение.
Процесс преобразования базы данных к виду, отвечающему
нормальным формам, называется нормализацией.
Нормализацией называют процесс устранения избыточности,
а также транзитивной и многозначной зависимости.
Устранение избыточности производится, как правило, за
счёт декомпозиции отношений таким образом, чтобы в каждом отношении хранились
только первичные факты.
Типы нормальных форм
Нормализация может применяться к таблице, которая
представляет собой правильное отношение.
Первая нормальная форма (1NF)
Отношение находится в первой нормальной форме
Отношение
находится в 1-й нормальной форме, если оно соответствует свойствам отношений.
1.
Уникальность атрибутов. Из этого свойства вытекает
наличие у каждого кортежа первичного ключа.
2.
Неупорядоченность атрибутов. Для ссылки на значение атрибута всегда используется
имя атрибута.
3.
Неупорядоченность кортежей.
4.
Атомарность значений атрибутов.
т.е. среди значений домена не могут содержаться
множества значений (отношения).
В реляционной модели
отношение всегда находится в первой нормальной форме по определению понятия
отношение. Что же касается таблиц в существующих реляционных СУБД (SQL-СУБД),
то они могут не быть правильными отношениями и, соответственно, не находиться в
1NF.
Вторая нормальная форма (2NF)
Отношение находится во 2NF, если оно находится в 1NF и все неключевые
атрибуты функционально зависят от ключевого атрибута. Ключевым атрибутом может
быть PK или составной
PK.
В
результате исходное отношение декомпозируется на 2 или более отношения.
Название /→ ФИО клиента
Название /→ адрес клиента
Название /→ номер паспорта клиента
Название /→ ФИО сотрудника
Название /→ телефон сотрудника
Оператор
(назв., ФИО, тел...)
Клиент(ФИО клиента, пасп.данные, адрес)
Третья нормальная форма (3NF)
Отношение находится в 3NF тогда и только тогда, когда
оно находится во 2NF и отсутствуют транзитивные зависимости неключевых
атрибутов от ключевых. Если в отношении R(x,y,z) существуют
функциональные зависимости м-ду x→y, y→z, то говорят что z транзитивно
зависит от х (x→→z)
При решении
практических задач в большинстве случаев третья нормальная форма является
достаточной. Количество отношений на данном этапе нормализации совпадает с
количеством первичных ключей.
Нормальная
форма Бойса — Кодда (BCNF)
Это модификация третьей нормальной формы (в некоторых
источниках именно 3NF называется формой Бойса —
Кодда).
Таблица находится в BCNF, если она находится в 3NF, и
при этом отсутствуют функциональные зависимости атрибутов первичного ключа от неключевых атрибутов. Таблица может находиться в 3NF, но не
в BCNF, только в одном случае: если она имеет, помимо первичного ключа, ещё по крайней мере один возможный ключ. Все зависимые от
первичного ключа атрибуты должны быть потенциальными ключами отношения. Если
это условие не выполняется, для них создаётся отдельное отношение. Чтобы
сущность соответствовала BCNF, она должна находиться в третьей нормальной
форме. Любая сущность с единственным возможным ключом, соответствующая
требованиям третьей нормальной формы, автоматически находится в BCNF.
Четвёртая
нормальная форма (4NF)
Таблица находится в 4NF, если она находится в BCNF
(3NF) и не содержит многозначных зависимостей. Многозначная зависимость
наблюдается тогда, когда одному значению атрибута X соответствует много
значений атрибута Y.
Пятая нормальная форма (5NF)
Таблица находится в 5NF, если она находится в 4NF и между
всеми его атрибутами наблюдаются многозадачные зависимости. Его можно получить путём декартова произведения его проекции на каждый
атрибут.
5NF в большей
степени является теоретическим исследованием и практически не применяется при
реальном проектировании баз данных. Это связано со сложностью определения
самого наличия зависимостей «проекции — соединения», поскольку утверждение о
наличии такой зависимости должно быть сделано для всех возможных состояний БД.
Доменно-ключевая
нормальная форма (DKNF)
Отношение в ДКНФ не имеет аномалий модификации.
Другими словами, что бы ни менялось — ничего не потеряется, если соблюдены все
ограничения относительно ключей и доменов. Формулировка слишком общая, но суть
ее заключается в том, что если выполнять некоторые правила, то при любых
действиях с таблицей ее целостность не пострадает и вся необходимая информация
сохранится. Если рассматривать на примере, то правила
действуют примерно так: нельзя просто удалить категорию из таблицы категорий,
если с этой категорией связаны, например, продукты из таблицы продуктов. Прежде
чем удалять категорию, необходимо выполнить предварительные действия в таблице
продуктов (например, поле отвечающее за id категории этого товара нужно сделать NULL). 5NF отвечает
за связи между отношениями.
Шестая нормальная форма (6NF)
Таблица находится в 6NF, если она находится в 5NF и
удовлетворяет требованию отсутствия нетривиальных зависимостей. Зачастую 6NF
отождествляют с DKNF.
6. Операции над отношениями
Схема отношения – название отношения плюс перечисление его атрибутов
R(x,y,z).
Односхемное отношение – отношение, в котором атрибуты определены попарно
на одних и тех же доменах, и количество атрибутов совпадает. Операции
проводятся над односхемными отношениями.
Операции над отношениями
Объединение
UNION
Выполняется на двух односхемных отношениях, результатом
является новое отношение, схема которого совпадает с первыми двумя, а кортежи
принадлежат 1 и 2 отношению, исключая повторения.
Пересечение INTERSECTION
Выполняется на двух односхемных отношениях,
результатом является отношение, схема которого совпадает и с 1 и со 2
отношением, а кортежи присутствуют одновременно и в 1 и во 2.
Вычитание MINUS
Выполняется на двух односхемных отношениях,
результатом является отношение, схема которого совпадает и с 1 и со 2
отношением, а кортежи присутствуют только те, которые имеются в 1 отношении, но
не имеются во 2.
Декартово произведение
Выполняется на двух разносхемных
отношениях, результатом является отношение, схема которого содержит атрибуты 1
отношения и атрибуты 2 отношения, а кортежи являются результатом конкатенации
(сложения строк) кортежей 1 и 2 отношений с всеми
возможными сочетаниями. Эта операция полезна при объединении доменов.
Соединение JOIN
Выполняется на двух разносхемных
отношениях, при условии, что в отношении R1 и R2 имеется атрибут, определенный
на одном и том же домене, результатом является отношение, схема которого
включает атрибуты 1 отношения и 2 отношения, исключая повторяющиеся, а кортежи
содержат только те значения, которые совпадают по общему атрибуту.
Вертикальная проекция
Выполняется на 1 отношении, результатом является
отношение, содержащее 1 атрибут, на который выполнялась проекция и все значения
этого атрибута, неповторяющиеся.
Горизонтальная
проекция
Выполняется на 1 отношении, результатом является
отношение, схема которого совпадает с условием, а кортежи будут отвечать
условию. Условие задается атрибуту и его значению.
Деление
Выполняется на двух разносхемных
отношениях, при этом схема отношения R2 является подмножеством схемы отношения
R1. Результатом является отношение R3, схема которого содержит атрибуты R1, не
входящие в R2, а кортежи включают кортежи R1, удовлетворяющие условию R2. R1(x,y,z),R2(y,z),R3(x).
7. Модели
доступа к данных в
архитектуре «клиент-сервер»
«Клиент-сервер» - это модель взаимодействия компьютеров в сети. Как
правило, компьютеры не являются равноправными. Компьютер, управляющий тем или
иным ресурсом, принято называть сервером этого ресурса, а компьютер,
желающий им воспользоваться - клиентом.
Компоненты модели «клиент-сервер»
1 Компонент
представления (отображение, представление данных);
2 Прикладной
компонент (обрабатывает данные, перед отображением);
3 Компонент,
отвечающий за хранение данных и файлов и управление ими;
4 Программное
обеспечение среднего уровня (отвечает за взаимодействие): драйверы(ODBC),
технологии(API).
Если предполагается,
что проектируемая информационная система (ИС) будет иметь технологию
"клиент-сервер", то это означает, что прикладные программы,
реализованные в ее рамках, будут иметь распределенный характер. Иными словами,
часть функций прикладной программы (или, проще, приложения) будет реализована в
программе-клиенте, другая - в программе-сервере, причем для их взаимодействия
будет определен некоторый протокол. Выделяются четыре подхода.
Модель файлового сервера
(FileServer)
Файл-серверные
приложения — приложения схожи по своей структуре с локальными приложениями и
используют сетевой ресурс для хранения программы и данных. Функции сервера:
хранения данных и кода программы. Функции клиента: обработка данных происходит
исключительно на стороне клиента. Количество клиентов ограничено десятками.
FS-модель является базовой для локальных сетей персональных компьютеров.
Компьютер-клиент Компьютер-сервер +--------------+----------+ Запрос +--------------+------+ | Функции |Прикладные|-------->| Функции | | |представления | функции |<--------| доступа | БД | +--------------+----------+ Данные | к ресурсам | | +--------------+------+
Достоинства:
• Простота технологии;
• Нет высоких требований к серверу;
• Вся логика приложения выполняется клиентом.
Недостатки:
• Высокие требования к сети;
• Нет собственника данных;
• Нет синхронизации одновременного доступа;
• Серьезное требование к выполнению логики предметной
области.
Модель удаленного
доступа к данным (RemoteDataAccess)
Компонент
представления и прикладной компонент совмещены и выполняются на одном
компьютере. Запросы к информационным ресурсам направляются по сети к удаленному
компьютеру, который обрабатывает запросы и возвращает блоки данных.
Компьютер-клиент Компьютер-сервер +--------------+----------+ Запрос +--------------+------+ | Функции |Прикладные|-------->| Функции | | |представления | функции |<--------| доступа | БД | +--------------+----------+ Блок | к ресурсам | | данных +--------------+------+
Достоинства:
• Снижение требований к сети – возвращается только
результат запроса;
• Данные организованы в виде БД, структурированность
данных;
• СУБД будет проверять все ключи, связи и т.д.;
• Унифицированный интерфейс (в виде SQL-запроса);
• К одной СУБД может обратиться несколько клиентов
одновременно, многопользовательский режим.
Недостатки:
• Логика предметной области выполняется клиентом;
• Нет централизованного администрирования;
• Загруженный трафик.
Модель сервера БД (DataBaseServer)
Строится исходя из предположения, что процесс,
выполняемый на компьютере-клиенте, ограничивается функциями представления, в то
время как собственно прикладные функции реализованы в хранимых непосредственно
в базе данных процедурах, которые выполняются на компьютере-сервере БД .
Компьютер-клиент Компьютер-сервер +--------------+ Вызов +-----------+-------------+------+ | Функции |--------->| Прикладные| Функции | | |представления |<---------| функции | доступа | БД | +--------------+ Результат| | к ресурсам | | +-----------+-------------+------+
Достоинства:
• Снижение требований к сети;
• Централизованное администрирование;
• Второй компонент (прикладной) реализован в виде
триггеров, хранимых процедур, механизма оповещений, доменов;
• Разграничение прав доступа;
• Правила обработки данных хранятся вместе с данными.
Недостатки:
• Возрастают требования к серверу;
• Администратор – высококвалифицированный работник;
• Нет унифицированного языка для процедур и триггеров
в различных СУБД, то есть при смене СУБД придется их разрабатывать заново;
• Отсутствуют высокие графические возможности.
Модель сервера приложений (ApplicationServer)
Прикладные функции выполняются на удаленном компьютере.
Компьютер-клиент Компьютер-сервер Компьютер-сервер +--------------+ Вызов +-----------+ Запрос+----------+----+ | Функции ┐------>| Прикладные|------>| Функции | | |представления |<------| функции |<------| доступа | БД | +--------------+ Резул.| |API,CGI|к ресурсам| | +-----------+ +----------+----+ ^ | | | Компьютер-сервер | | Запрос +----------+----+ | +--------->| Функции | | +--------------| доступа | БД | API,CGI |к ресурсам| | +----------+----+
CGI-CommonGatewayInterface. За хранение данных отвечают СУБД (ORACLE, SQL Server, Informix, Postgres, PostgreSQL).
Требования к серверу:
• Надежность;
• многопользовательский режим;
• Оптимальное выполнение запросов.
Достоинства:
• «тонкий» клиент;
• администрирование БД;
• реализация всей логики представления прикладного
компонента (графика) и обработки на сервере;
• политика безопасности;
• требования к сети минимальны.
Недостатки:
• Требования к серверу (установка дополнительного
сервера, который хранит данные-дубликаты);
• Требования к разработчику.
8. Понятие
транзакций. Свойства, обработка, блокировки транзакций
Транзакция - последовательность операторов языка SQL, которая
рассматривается как единое, неделимое действие над БД, осмысленное с точки
зрения пользователя. Как правило, реализует прикладную функцию.
Транзакция - атомарное действие над БД, переводящего ее из
одного целостного состояния в другое целостное состояние. Другими словами, транзакция
- это последовательность операций, которые должны быть или все выполнены или
все не выполнены (все или ничего).
Свойства
ACID-транзакции
Atomicity
– атомарность. Транзакция должна быть выполнена целиком или не выполнена
полностью.
Consistency
– согласованность. По мере выполнения транзакции данные переходят из одного
согласованного состояния в другое. Выполнение транзакции не должно нарушать
целостность БД.
Isolation
– изолированность. Конкурирующие за данные транзакции выполняются последовательно,
но для пользователя это выглядит так, как будто они выполняются параллельно.
Durability
– долговечность. Если транзакция завершена успешно, то никакие изменения в
данных, которые ею сделаны, не могут быть потеряны.
Варианты
окончания транзакции
1.
оператор COMMIT
означает успешное завершение транзакции, все изменения, внесненные
в базу данных делаются постоянными
2.
оператор ROLLBACK
прерывает транзакцию и отменяет все внесенные ею изменения
3.
успешное заверешение программы, инициировавшей транзакцию, означает
успешное завершение транзакции (как использование COMMIT)
4.
ошибочное
завершение программы прерывает транзакцию (как ROLLBACK)
Ведется журнал
транзакции, чтобы можно было откатить транзакцию. В журнале хранятся записи
в таблице. Хранится 2 состояния: до изменения и после.
Проблемы работы транзакций
1) Проблема
несохраненных изменений. Одна транзакция обращается к данным и изменяет, а
другая «работает» с измененными данными. В это время первая транзакция
откатывается.
2) Проблема
несохраненных данных. Две транзакции обращаются к данным одновременно и
пытаются изменить их. Изменения одной сохраняются, а другой нет.
Правила
обработки транзакций
1) Механизм блокировки объектов. Если транзакция
обращается к какому-то объекту, то для других транзакций этот объект должен
быть заблокирован.
Методы "борьбы":
• Блокировка всей БД;
• Блокировка на уровне страниц (части таблиц);
• Блокировка на уровне записи (Oracle).
2) Приоритеты. Чаще
всего приоритеты назначаются по времени старта транзакции.
Механизм
блокировки
Фактически сериализация
транзакций гарантирует, что каждый пользователь (программа), обращающаяся к
базе данных, работает с ней так, как будто не
существует других пользователей (программ), одновременно с ним обращающихся к
тем же данным. Для практической реализации этой дисциплины большинство
коммерческих СУБД используют механизм блокировок. СУБД блокирует фрагмент
таблицы (таблицу) до тех пор, пока транзакция не будет зафиксирована или
отменена.
Если СУБД
реализована таким образом, что может захватывать для выполнения транзакции
отдельные строки таблицы, то скорость обработки транзакции существенно
повышается. Блокировка на уровне записей (строк) позволяет добиться
максимальной производительности за счет того, что захватываемый объект (запись)
является минимальной структурной единицей базы данных.
Основными
видами блокировок являются:
- блокировка со взаимным
доступом, называемая также S-блокировкой
(от Shared locks) и блокировкой
по чтению.
- монопольная блокировка (без взаимного доступа), называемая также X-блокировкой
от (eXclusive locks)
или блокировкой по записи. Этот режим используется при операциях
изменения, добавления и удаления объектов.
При этом:
- если транзакция налагает на объект X-блокировку,
то любой запрос другой транзакции с блокировкой этого объекта будет
отвергнут.
- если транзакция налагает на объект S-блокировку,
то
- запрос со стороны другой транзакции с X-блокировокй на этот объект будет отвергнут
- запрос со стороны другой транзакции с S-блокировокй этого объекта будет принят
9. СУБД. Понятие, основные функции, требования к
серверу баз данных
СУБД – комплекс программных и технических средств,
обеспечивающий оптимальное управление, манипулирование и хранение данных.
Поддерживает трехуровневую организацию данных (внешнюю, внутреннюю и
концептуальную модели данных).
Внутренняя
модель - модель данных низшего
(физического) уровня в архитектуре СУБД, отражающая представление данных во
внешней памяти и методы доступа к ним.
Внешняя
модель - модель данных внешнего
уровня в архитектуре СУБД, отражающая представление пользователя о базе данных
(подсхема базы данных и ее описание).
Концептуальная
модель - информационная модель
предметной области в терминах конкретной СУБД, содержащая полный набор данных и
связей между ними. В архитектуре СУБД представляет промежуточный между внешним и внутренним уровень.
Воронка
Сенко:
Основой воронки Сенко лежит
концептуальный уровень. Структура данных или описание разрабатывается 1 раз для
предметной области и могут быть представлены в виде
концептуальной модели данных. Концептуальная модель данных опирается на тип
СУБД (Реляц., Иерарх., ОО).
На основе концепт. модели
можно разработать много различных приложений представления данных. Они
составляют внешний уровень. На основе концепт. МД можно сгенерировать схемы
данных в различных СУБД. Способ организации этих структур наз-ся
внутреннем уровнем.
Основные
функции СУБД
1) управление данными во внешней памяти (на дисках);
2) управление данными в оперативной памяти с
использованием дискового кэша;
3) журнализация изменений, резервное копирование и
восстановление базы данных после сбоев;
4) поддержка языков БД (язык определения данных, язык
манипулирования данными).
Требования к СУБД
Они многокритериальны.
1. Моделирование данных
• Поддержка одной из известных моделей данных
• Поддержка триггеров и хранимых процедур
• Средства поиска (в том числе и контекстного)
• Типы данных: базовые (основные) и возможность их
расширения
• Язык запросов: поддержка стандарта языка запросов
2. Архитектура и функциональные возможности
• Мобильность – независимость от среды
• Масштабируемость –
увеличение размера системы без потери функциональности
• Распределенность
(распределенная БД, распределение доступа к БД)
• Сетевые возможности – поддержка сетевых протоколов и
служб
3. Контроль работы системы
• Контроль использования памяти компьютера
(оперативной, дисковым пространством)
• Автонастройка -
возможность самоконфигурирования
4. Производительность
• Рейтинг TPC (Transaction Per Cent) – количество транзакций
(запросов) на единицу стоимости системы
• Возможности параллельной архитектуры (выполнение
процессов на разных процессорах, параллельный сервер)
• Возможности оптимизирования запросов (построение
плана запросов, опирающегося на структуру данных, мощность отношений и операции
языка запросов)
5. Надежность
• Восстановление после сбоев
• Резервное копирование
• Откат изменений
• Многоуровневая система защиты
6. Дополнительные
• Средства проектирования (БД и приложений)
• Многоязыковая поддержка
• Возможность разработки web-приложений
• Качество и полнота документации
• Модель формирования стоимости
Требования
к серверу СУБД
Требования на соответствие реляционной модели), в 70-е
годы сформулировал Кодд.
1. Информационное. Вся информация, хранящаяся
в БД, должна быть представлена единым образом: в виде значений в таблице.
2. Правило гарантированного логического
доступа. К любому значению, хранящемуся в БД, должен обеспечиваться доступ
путем указания таблицы, названия атрибута и значения PK
3. Правило отсутствия значения. В любой
СУБД имеется специальный индикатор для обозначения пустых значений (NULL).
Значения не введены, либо не могут храниться.
4. Правило динамического реляционного
каталога. Описание БД выглядит также как обычные данные.
5. Правило полноты языка работы с данными
В любой
СУБД должен быть хотя бы 1 язык, выразимый в виде командных строк, который
позволял бы формулировать:
• Описание данных
• Определение правил целостности
• Манипулирование данными
• Определение таблиц-представлений (View)
• Определение правил авторизации
• Границы транзакции
6. Правило модификации таблиц-представлений
(view). В СУБД должен существовать корректный
алгоритм, позволяющий для каждой view определять во
время ее создания может ли она использоваться для вставки/удаления
строк.
7. Правило множественности операций.
Возможность оперирования над реляционными таблицами распространяется не только
на выдачу информации, но и на вставку, модификацию и удаление данных.
8. Правило физической независимости.
Внешние прикладные программы не должны страдать от изменения правил доступа к
данным. Это касается физического уровня.
9. Требование логической независимости.
Внешние программы не должны страдать от изменений в структуре данных.
10. Правило сохранения целостности.
Целостность сущности (уникальность всех кортежей в отношении – обеспечивается
PK) и целостность данных по ссылкам (в зависимой сущности всегда есть атрибут
FK, определенный на домене, что и PK главной сущности). Никакие прикладные программы
не могут изменить эти два вида целостности.
11. Правило привилегий реляционного языка.
Если СУБД имеет свой внутренний язык работы с данными, то вначале выполняются
команды реляционного языка (SQL), а потом команды внутреннего языка.
12. Правило динамического каталога. Все
объекты БД должны отображаться как объекты обычного каталога.
Требования к серверу базы данных
1. Прежде всего, он должен
быть мощным и производительным, эффективно решать как задачи оперативной
обработки транзакций, так и задачи обработки сложных аналитических запросов,
причем делать одно не в ущерб другому.
2. В то же время сервер базы
данных должен играть в модели взаимодействия "клиент-сервер" активную
роль, иметь возможность оказывать оперативное влияние на работу клиентов.
3. Он должен быть
программируемым - то есть должны существовать средства, позволяющие выполнять
операции над данными независимо от прикладных программ.
4. Сервер БД должен быть
настраиваемым, то есть в арсенале СУБД необходимы средства тонкой настройки на
разнообразные режимы работы.
10. Возможности
CASE-средств для проектирования баз данных
Средства
автоматизации проектирования приложений (CASE-средства) предназначены
для анализа предметной области, для проектирования и генерации программ
информационных приложений.
Проблемы ручной разработки:
1.
Неадекватная
спецификация требований;
2.
Неспособность
обнаруживать ошибки;
3.
Низкое качество
документации;
4.
Затянутый цикл
разработки.
Могут существовать в
виде отдельных утилит или интегрированной среды проектирования. Системы CASE
реализуют либо структурные, либо объектно-ориентированные методы анализа,
проектирования и программирования. Кроме того, для каждой методики
проектирования несколько различаются нотации схематических описаний.
Различают следующие виды
систем автоматизации проектирования приложений: независимые CASE-системы
(например, IDEF/Design), системы, интегрированные с
СУБД (Oracle Designer/2000);
системы проектирования БД (ErWin).
Интегрированное
CASE-средство (или комплекс средств, поддерживающих полный жизненный цикл
программного обеспечения) содержит следующие компоненты:
1.
репозиторий, основа CASE-средства. Он должен обеспечивать
хранение версий проекта и его отдельных компонентов, синхронизацию поступления
информации от различных разработчиков при групповой разработке, контроль
метаданных на полноту и непротиворечивость;
2.
графические
средства анализа и проектирования, обеспечивающие создание и редактирование
иерархически связанных диаграмм (DFD, ER-диаграмма и др.), образующих модели
информационных систем;
3.
средства
разработки приложений (генераторы кодов);
4.
средства
конфигурационного управления;
5.
средства
документирования;
6.
средства
тестирования;
7.
средства
управления проектом;
8.
средства реинжиниринга.